前言
来到腾讯实习后,有幸八月份开始了腾讯办公助手PC端的开发。因为办公助手主推的是移动端,所以导师也是大胆的让我们实习生来技术选型并开发,他来做code review。之前也学习过React,当然也是非常合适这一次的开发。
我会梳理这一个月来,自己对架构的思考过程和踩过的坑。当然这一切都不一定是最佳的,所以希望能有更多的建议和讨论。
例子所需库:Webpack、React、Immutable。其中Webpack用于前端构建,如果不清楚的同学可以看这里:webpack前端构建体验。
出现场景
一般来说,React作为一个高效的UI Library,如果合理使用是很难出现性能问题的。它内部提供了虚拟DOM搭配上Diff算法,和子组件必要的key属性,都是非常优秀的优化了绝大部分的性能。
但是我们来模拟一个场景,在一个数组里有10000个对象,我们把这个数组的数据渲染出来后,其中一个属性用于控制页面状态。
在这里我希望大家知道有一点就是,当父组件的状态state发生变化时,传入state的子组件都会进行重新渲染。
下面我们来模拟一下这种情况,一起来看看。
1 | /** |
这个就是我们的有性能问题的组件。当我们去点击选框时,因为父组件的state传到了子组件的props里,我们就会遇到10000个子组件重新渲染的情况。所以表现出来的情况就是,我点一下,等个一两秒那个框才真正被勾上。我相信用户在这一秒内肯定已经关掉页面了。
如果对React很熟悉的人,肯定知道一个生命周期的Hook,就是shouldComponentUpdate(nextProps, nextState)。这个API就是用来决定该组件是否重新Render。所以我们肯定很开心的说,只要属性的checked值不变,就不渲染呗!
1 | // return true时,进行渲染;false时,不渲染 |
就这么简单么~我保存编译JSX后,迫不及待的刷新浏览器看一看了。一按
嗯,呵呵,组件都不会渲染了…那说明this.props.data和nextProps.data的数据是一致的,这怎么可能?!我明明是通过父组件的函数修改了数组然后重新setState的呀!
修改数组……嗯,当时我就意识到这肯定又和引用类型有关。我相信大家既然能看到这里,相信基础都是有的,就是数据的基本类型和引用类型的差别,但是我还是乐意再用代码展示一次。
1 | // 基本类型,number boolean string undefined null |
我们明显可以看到它们的差别,我们这里着重注意一下引用类型。因为变量不再直接存值,而是变成了存指针。所以我们的每一次都同一个指针所指内存进行修改时,都会影响到拥有该指针的变量。这里当然a和b都是指的同一个对象,所以他们修改的数据也同样是同步的。
对,我们的this.props.data和nextProps.data指的是同一个东西,所以任何修改都不会让它们区分开。那这样我们是不是就要开始考虑如何进行深拷贝?
深拷贝表示只是路过打个酱油
我们在开发过程中,既可以享受到使用引用类型的特点带来的便利,但是同时也会忍受到非常多稀奇古怪的问题,总而言之,弊大于利。
思路其实就是将一个引用类型通过递归的方式,逐层向下取最小的基本类型,然后拼装成一样的引用类型。一看就是耗性能的主啊!如果真有这个深拷贝需求的同学,这里推荐的是lodash库的_.cloneDeep方法,它是据我所知最完善的深拷贝方法。
当然如果你的引用类型并不复杂,例如没有函数或正则,只包含扁平化的数据时,我这里推荐一个奇淫巧计。
1 | var newData = JSON.parse(JSON.stringify(data)); |
其实在我们这次这个案例里,就非常适合这个JSON序列化后再反序列化的方法,因为我们的数据其实也就是扁平化的。我们把它放到函数内看一下效果。
1 | toggleChecked(event){ |
这个世界瞬间清爽多了。但是我们知道,在真正的开发过程中,不一定可以用这种奇淫巧计的,那我们除了实在没办法耗性能的deepClone,我们还能怎么办?怎么办!?
Immutable Data
Facebook自家有一个专门处理不可变数据的库,immutable-js。我们知道,React其实是非常接近函数式编程的思想的,我们可以用下面这个式子来表示React的渲染。
1 | UI = fRender(state, props); |
Immutable Data(不可变数据)的思想就是,不存在指向同一地址的变量,所有对Immutable Data的改变,最终都会返回一份新复制的数据,各自的数据并不会互相影响。在构建大型应用时,应该非常注意这样的数据独立性,不然你连数据在哪儿被改了你或许都不知道。那说了这么多它的概念,实际使用的时候是怎么样的?
1 | // 这段代码可以直接在Immutable的文档页面的控制台执行 |
我们执行后,确实原有的数据已经不可变了,又新生成了一个新的不可变数据,其实这里有个非常有趣的应用场景就是撤销。不用再担心引用类型数据的变化,因为一切数据都被你把控了。
我相信有人肯定好奇说,我每一次操作数据时都deepClone一下,也可以达到这种效果呀,这里的实现有什么不一样吗?deepClone是通过递归对象进行数据的拷贝,而Immutable数据的实现则是仅仅拷贝父节点,而其他不受影响的数据节点都是共享的用同一份数据,以大大提升性能。我们需要做的仅仅是将原生的数据转化成Immutable数据。
我知道仅仅通过语言是很难生动表现出来的,所以找到几幅图来进行解释。
我们需要修改某个节点的数据,这个节点用黄色标了出来。
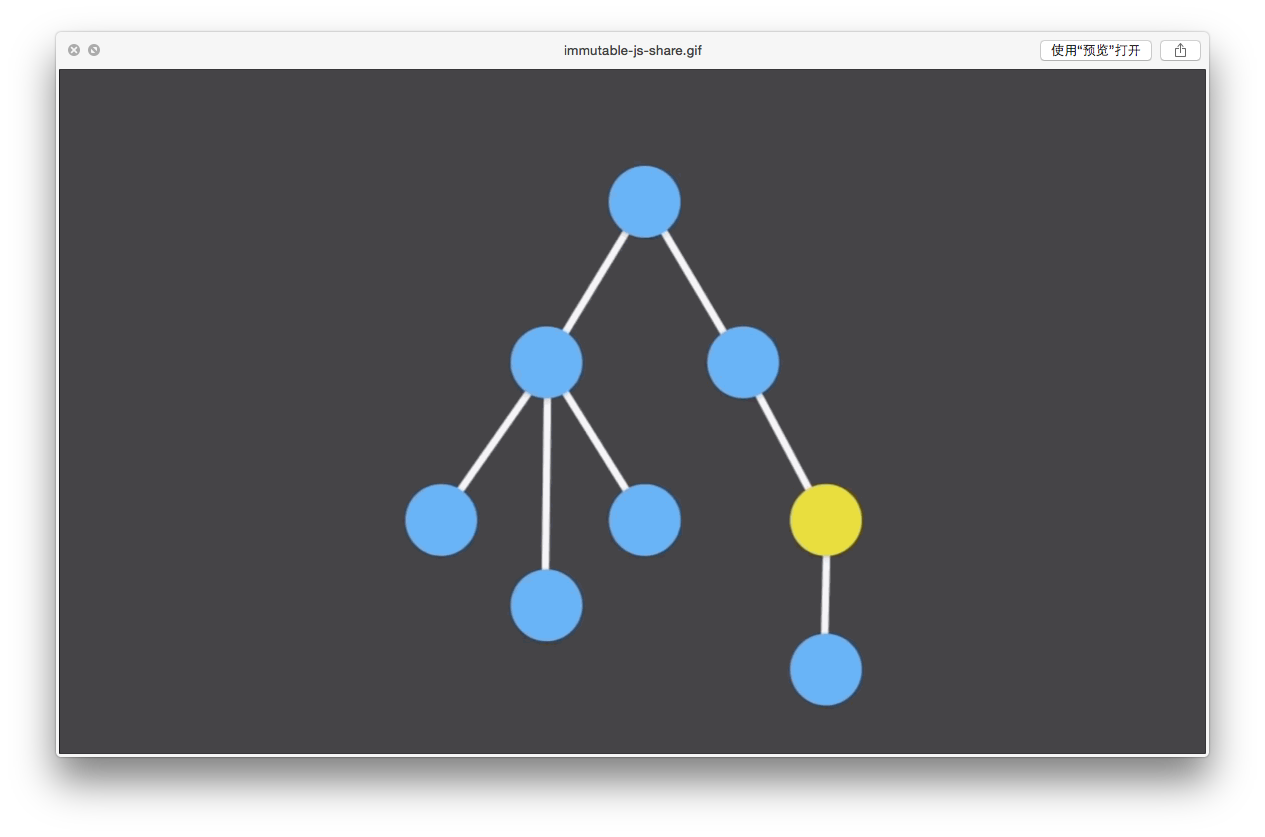
按照我们刚才所说的,仅对父节点进行一次数据的拷贝,我们把全新的数据拉出来,拷贝的是绿色的节点。
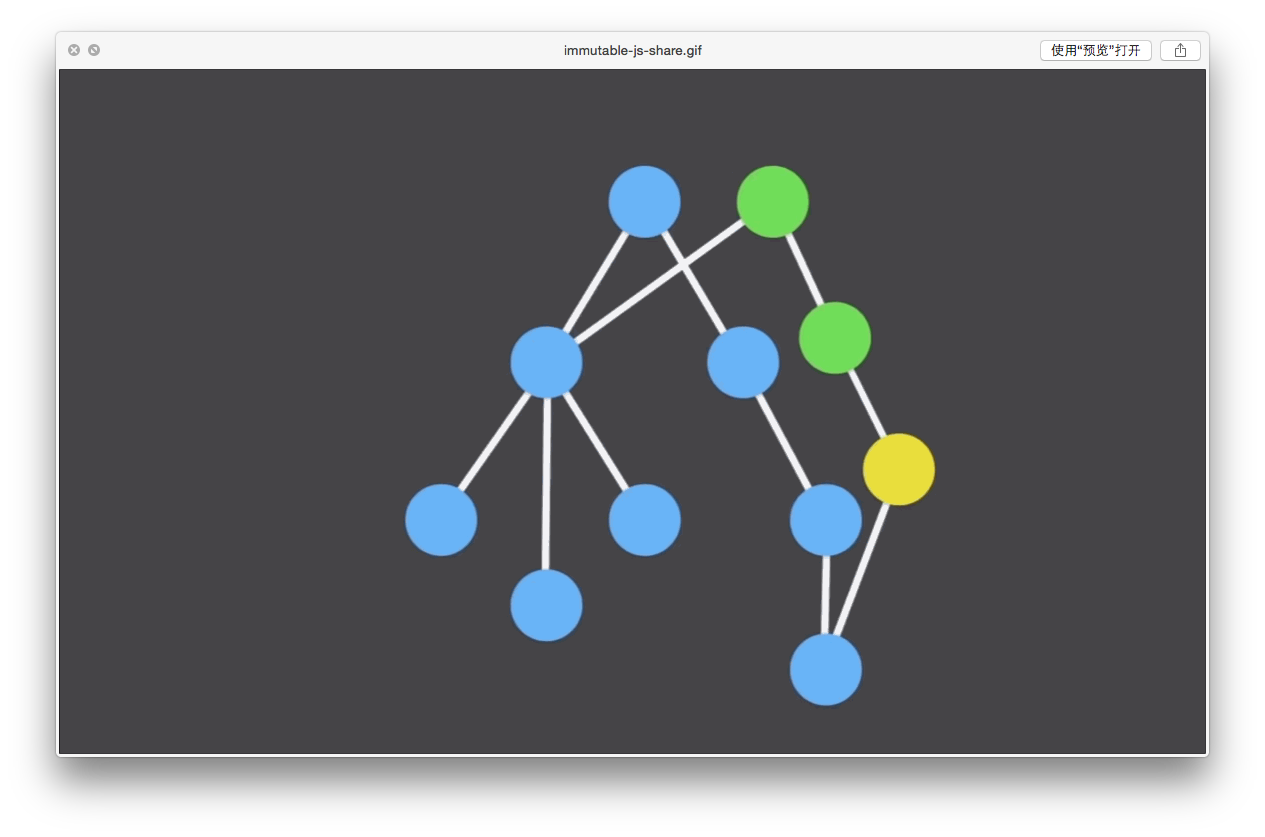
而其他的节点数据其实并不受影响,所以我们可以直接使用他们的内存地址,共享一份数据。共享的数据,我们用橙色标出。

最后我们以最优的性能得到了一份全新的数据。

当我们在shouldComponentUpdate里判断是否更新时,变化的数据是新的引用,而不变的数据是原来的引用,这样我们就可以非常轻松的判断新旧数据的差异,从而大大提升性能。那我们知道了这个Immutable可以很好的解决我们的痛点之后,我们该如何使用到我们的实际项目中呢?其实很简单的,就是数据初始化时,就让它变成Immutable数据,然后之后对数据的操作就可以参照一下文档了,这里我直接重写了demo,其实也就是把取值和赋值做个改变,我会用注释标识出来。
1 | /** |
就这样,我们非常优雅的解决了引用类型带来的问题。其实Immutable的功能并不只这些。它内部提供了非常多种的数据结构以供使用,例如和ES6一致的Set,这种特殊的数组不会存有相同的值。相信利用好不同的数据结构,会非常有利于你构建复杂应用。
PureRenderMixin表示也要来打个酱油
这里插多个React.addons内添加的东西,在我一开始探索这些性能相关问题的时候,我就注意到了这个东西。它会自行为该组件增添shouldComponentUpdate,对现有的子组件的state和props进行判断。但是它只支持基本类型的浅度比较,所以实际开发时并不能直接拿来使用。但是! 我们一旦使用了Immutable数据后,比较是否是同一指针这样的事情,自然就是浅比较,所以换句话而言,我们可以使用PureRenderMixin配合上Immutable,非常优雅的实现性能提升,而且我们也不用再手动去shouldComponentUpdate进行判断。
1 | var React = require("react/addons"); |
总结
我相信这次提供的方法,已经可以非常优雅的解决绝大部分的性能问题了。但如果还不行,那么你可能要对你的业务逻辑代码进行优化了。下一篇,我将会介绍一下React-hot-loader这一开发神器,它可以利用webpack的模块热插拔的特性,实时对浏览器的js进行无刷新的更新,非常的酷炫!我在配置它的过程中也摸了一些坑,所以希望能帮助大家跳过这个坑。相信如果能好好使用它,将会大大提升大家的开发效率。

